哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出现在各类的面试题中,重要性可见一斑。本文会对java集合框架中的对应实现HashMap的实现原理进行讲解,然后会对JDK8的HashMap源码进行分析。
什么是哈希表
在讨论哈希表之前,我们先大概了解下其他数据结构
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
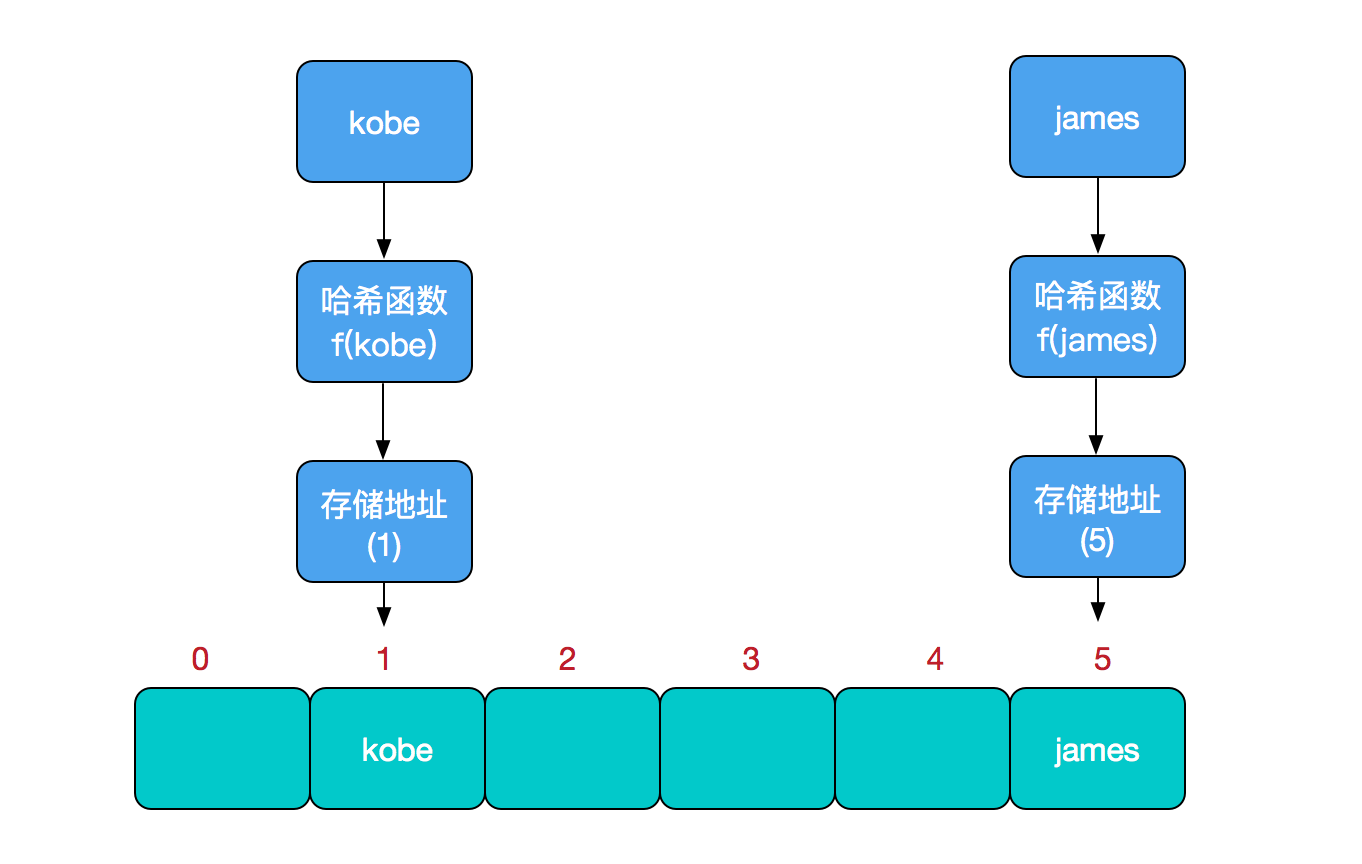
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
JDK8中HashMap的实现原理
在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
下图中代表jdk1.8之前的hashmap结构,左边部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
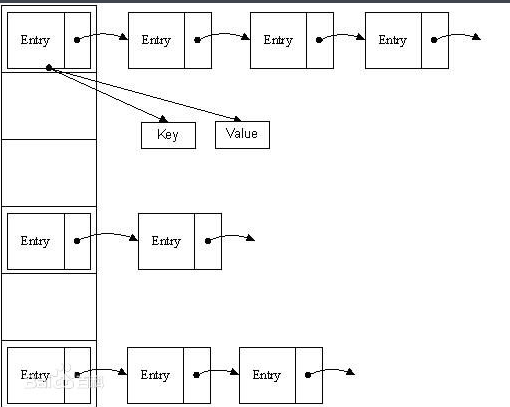
jdk1.8之前的hashmap都采用上图的结构,都是基于一个数组和多个单链表,hash值冲突的时候,就将对应节点以链表的形式存储。如果在一个链表中查找其中一个节点时,将会花费O(n)的查找时间,会有很大的性能损失。到了jdk1.8,当同一个hash值的节点数不小于8时,不再采用单链表形式存储,而是采用红黑树,如下图所示。
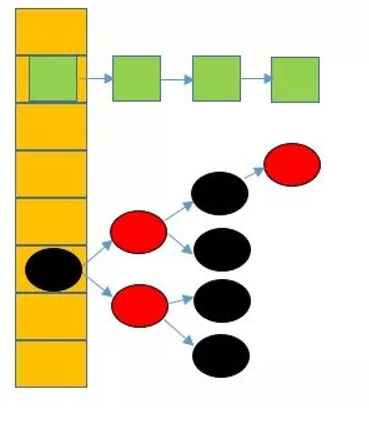
JDK8 HashMap源码解析
类注释翻译
点开HashMap,迎面扑来的便是一大段关于HashMap的类注释,一个屏幕都放不下。
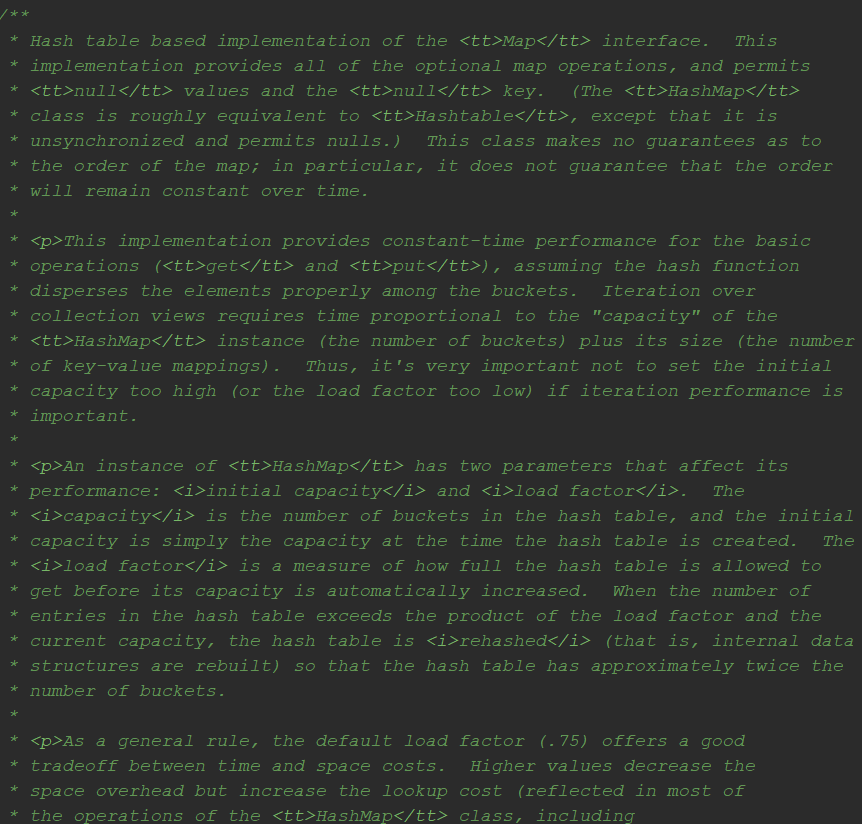
通过这些注释,我们可以对HashMap的特性有一个大致的了解,接下来先尝试翻译一下,翻译不对的地方欢迎留言指出。
HashMap是Map接口的实现类,它基于哈希表,提供了所有可选的map操作,并允许null的值和null键(HashMap类大致相当于Hashtable ,区别在于它是不同步的,并允许null)。这个类不保证map的顺序; 特别是,它不能保证顺序是一直保持不变的。
如果Hash函数能够很完美的分散各个元素到桶上,对于get和put这些基础操作,HashMap可以提供恒定的时间性能。遍历HashMap的时间与实例的容量(桶数)加上其大小(key-value数量)成比例。因此,如果迭代性能很重要,则不要将初始容量设置得太高(或负载因子太低)。
HashMap实例有两个影响其性能的参数: 初始容量和负载因子 。_容量_是哈希表中的桶数,初始容量是创建哈希表时的容量。 负载因子决定扩容前哈希表能达到多少容量。 当哈希表中的条目数超过加载因子和当前容量的乘积时,哈希表会被重新哈希(也就是说,内部数据结构被重建),容量扩充为之前的两倍。
默认加载因子(0.75)在时间和空间成本之间提供了良好的权衡。 大于0.75会减少空间开销,但会增加查询成本(HashMap类的大多数操作中,包括get和put)。 在设置其初始容量时,应考虑预期key-value数及其加载因子,以便最小化扩容次数。 如果初始容量大于最大条目数除以加载因子,则不会发生扩容操作。
如果一个HashMap实例要存放很多的key-value,在初始化的时候指定一个大的容量比扩容性能更好。如果很多key的HashCode()相同,肯定会导致HashMap性能降低。如果这些间是Comparable(可比较)的,这个类或许可以通过键之间的比较顺序来改善性能。
需要注意的是HashMap不是同步的,如果多个线程同时访问HashMap,并且至少有一个线程在对其结构进行修改,则必须在外部加上同步(结构修改是添加或删除一个或多个映射的任何操作;仅更改与实例已包含的键关联的值不是结构修改)。
这通常通过在一个封装map的对象上加上同步来解决。如果不存在这样的对象,则map应该使用Collections.synchronizedMap方法进行转换。这一步最好在创建的时候就完成,防止出现意外之外的不同步访问。
1 | Map m = Collections.synchronizedMap(new HashMap(...)); |
所有这个类的“集合视图方法(collection view methods)”返回的迭代器都是快速失败( fail-fast)的:在迭代器创建之后,除了迭代器自己的remove方法之外,任何时候对map进行结构修改,迭代器都将抛出ConcurrentModificationException。因此,面对并发修改,迭代器会快速而干净地失败,而不是在不确定的时间冒着不确定的风险。
请注意,迭代器的快速失败行为无法阿紫存在不同步的并发修改时做出任何硬性保证。快速失败迭代器会尽最大努力抛出ConcurrentModificationException。因此,不要编写这个异常的程序:迭代器的快速失败行为应仅用于检测错误。
这个类是Java集合框架的一员
重要字段
1 | //实际存储的key-value键值对的个数 |
构造方法
1 | HashMap() |
HashMap有4个构造器,最后一个很少使用,这里就不讲了。其他构造器如果用户没有传入initialCapacity 或者loadFactor这两个参数,会使用默认值,initialCapacity默认为16,loadFactory默认为0.75。
1 | /** |
可以看到,无参构造非常简单,只是对加载因子赋了默认值,这个时候HashmMap内部的数组其实还没有被初始化为null。对于使用无参构造创建的HashMap,会在第一次put的时候初始化数组,put方法后面会细讲。
1 | public HashMap(int initialCapacity, float loadFactor) { |
tableSizeFor()方法是JDK8出现了,它的作用是返回返回大于输入参数且最近的2的整数次幂的数。比如输入3,则返回4;输入5,则返回8。这里的算法很是巧妙,对于性能有很大提升,感兴趣可以看这篇博客Java8 HashMap之tableSizeFor
1 | /** |
put()
1 | public V put(K key, V value) { |
put()方法涉及的成员变量或成员方法
成员变量transient Node<K,V>[] table
table是HashMap用来实际存放元素的数组,它在首次使用时会被初始化。它的长度始终是2的幂次方。在某些操作中长度可能为0。
1 | /** |
成员变量阔值threshold
1 | /** |
静态方法hash()
1 | static final int hash(Object key) { |
我们知道HashMap的容量是2的幂次方,那么newCap - 1的高位应该全部为0。如果e.hash值只用自身的hashcode的话,那么index只会和e.hash低位做&操作。这样一来,index的值就只有低位参与运算,高位毫无存在感,从而会带来哈希冲突的风险。所以在计算key的哈希值的时候,用其自身hashcode值与其低16位做异或操作。这也就让高位参与到index的计算中来了,即降低了哈希冲突的风险又不会带来太大的性能问题。–出自掘金,作者:特立独行的猪手
方法resize()
1 | /** |
get()
1 | public V get(Object key) { |
使用getNode()方法取值,没有返回null
1 | final Node<K,V> getNode(int hash, Object key) { |
Node数据节点解析
我们知道HashMap底层维护了一个Node数组,它是最基础的数据节点,接下来便揭开Node数组的神秘面纱。
1 | static class Node<K,V> implements Map.Entry<K,V> { |
首先看它的类声明,实现了Map.Entry接口。Entry接口定义了一些Map实现类公用的方法
可以看到Node类其实非常简单,维护了四个属性 key、value、key的Hash值和下一个节点。我们看下是怎么用的。
上面的在put()方法中已经提到过,当我们put一个key-value时,如果key不存在,或者说没有发生哈希冲突时,就会new一个新的节点。
1 | ... |
看下newNode方法,非常简单就是调用了Node的构造函数
1 | Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) { |
当发生hash碰撞的时候,首先是已链表的形式存放。实际上就是创建一个新的Node节点,然后复制给之前的Node元素的next属性。
1 | ... |
当链表的长度大于8的时候,转化为红黑树,这个时候其实是把Node链表转变为另外一个数组结构ZreeNode。
1 | ... |
1 | /** |
限于篇幅,此处不深入讲解红黑树这种数据结构以及其实现,后面会单独开一篇讲。
HashMap的初始容量应该如何指定
同ArrayList一样,我们在new Hashmap()的也最好能够指定它的初始容量大小,目的就是为了提升效率,也能在一定程度上节约内存,那么这个初始容量应该如何指定?看过源码后,相信应该已经知道答案。
在HashMap中有一个成员变量threshold,它的计算方式是初始容量*加载因子。当填充度大于threshold,则会进行扩容。所以如果我们在知道或者大致估计HashMap的存放数量之后,除以0.75,在选择大于此结果的最近的2的幂次方即可(这一步可忽略,因为HashMap会自动帮你完成)。
有的同学可能会有HashMap最小容量是16的错觉,其实并不是,16只是我们在没有指定初始容量后,第一次put元素时初始化的容量。我们完全可以将容量指定为2。
总结
- JDK1.8之后HashMap底层是数组+链表+红黑树
- HashMap线程不安全,我们可以使用Collections.synchronizedMap包装为线程安全HashMap或者使用HashTable,CurrentHashMap
- HashMap的默认初始容量为16,加载因子是0.75,填充度达到75%后,会扩容至原来的2倍
参考:
https://juejin.im/post/5aa47ef2f265da23a0492cc8#heading-4
https://juejin.im/post/58f2f47061ff4b0058f4b7cc#heading-7
https://docs.oracle.com/javase/8/docs/api/

