背景
目前yjsj_jianyancgjg已接近1亿,yysy_jianyanbg已达到1000万,且这两张表数据增长十分快速,为了走可持续发展道路,决定对这两张表进行水平拆分。
被淘汰的tidb
上周对tidb进行的压力测试,结果表明在持续并发下,tidb不够稳定,会莫名出现查询缓慢导致请求失败的情况,这在业务系统中是不能忍受的,所以排除将数据迁移至tidb的方法,还是使用传统的分库分表方案。
中间件的选择
实现分库分表的方式有很多种,市面上也有很多的框架或工具。从切入点来说,整体分为五种:

- 编码层
在同一个项目中创建多个数据源,采用if else的方式,直接根据条件在代码中路由。Spring中有动态切换数据源的抽象类,具体参见
AbstractRoutingDataSource。
如果项目不是很庞大,使用这种方式能够快速的进行分库。但缺点也是显而易见的,需要编写大量的代码,照顾到每个分支。当涉及跨库查询、聚合,需要循环计算结果并合并的场景,工作量巨大。
如果项目裂变,此类代码大多不能共用,大多通过拷贝共享。长此以往,码将不码。
- 框架层
这种情况适合公司ORM框架统一的情况,但在很多情况下不太现实。主要是修改或增强现有ORM框架的功能,在SQL中增加一些自定义原语或者hint来实现。
通过实现一些拦截器(比如Mybatis的Interceptor接口),增加一些自定义解析来控制数据的流向,效果虽然较好,但会改变一些现有的编程经验。
很多情况要修改框架源码,不推荐。
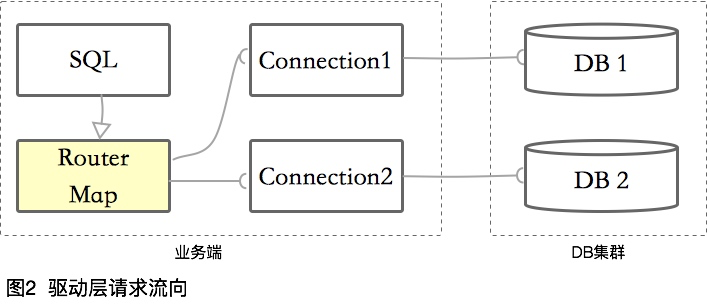
-驱动层
基于在编码层和框架层切入的各种缺点,真正的数据库中间件起码要从驱动层开始。什么意思呢?其实就是重新编写了一个JDBC的驱动,在内存中维护一个路由列表,然后将请求转发到真正的数据库连接中。
像TDDL、ShardingJDBC等,都是在此层切入。
包括Mysql Connector/J的Failover协议
(具体指“load balancing”、“replication”、“farbic”等),
也是直接在驱动上进行修改。
请求流向一般是这样的:
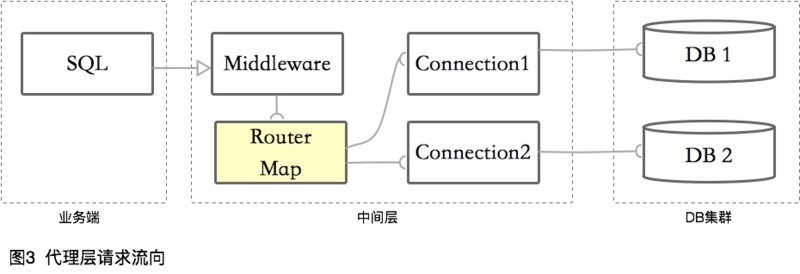
- 代理层
代理层的数据库中间件,将自己伪装成一个数据库,接受业务端的链接。然后负载业务端的请求,解析或者转发到真正的数据库中。
像MySQL Router、MyCat等,都是在此层切入。
请求流向一般是这样的:
- 实现层
SQL特殊版本支持,如Mysql cluster本身就支持各种特性,mariadb galera cluster支持对等双主,Greenplum支持分片等。
需要换存储,就不在讨论之列了。
驱动层和代理层对比
通过以上层次描述,很明显,我们选择或开发中间件,就集中在驱动层和代理层。在这两层,能够对数据库连接和路由进行更强的控制和更细致的管理。但它们的区别也是明显的。
驱动层的特点
- 仅支持JAVA,支持丰富的DB
驱动层中间件仅支持Java一种开发语言,但支持所有后端关系型数据库。如果你的开发语言固定,后端数据源类型丰富,推荐使用此方案。

- 占用较多的数据库连接
驱动层中间件要维护很多数据库连接。比如一个分了10个 库 的表,每个java中的Connection要维护10个数据库连接。如果项目过多,则会出现连接爆炸(我们算一下,如果每个项目6个实例,连接池中minIdle等于5,3个项目的连接总数是 1065*3 = 900 个)。像Postgres这种每个连接对应一个进程的数据库,压力会很大。
- 运维负担小
所有集群的配置管理都集中在一个地方,运维负担小,DBA即可完成相关操作。
- 数据聚合在业务实例执行
数据聚合,比如count sum等,是通过多次查询,然后在业务实例的内存中进行聚合。
路由表存在于业务方实例内存中,通过轮询或者被动通知的途径更新路由表即可。
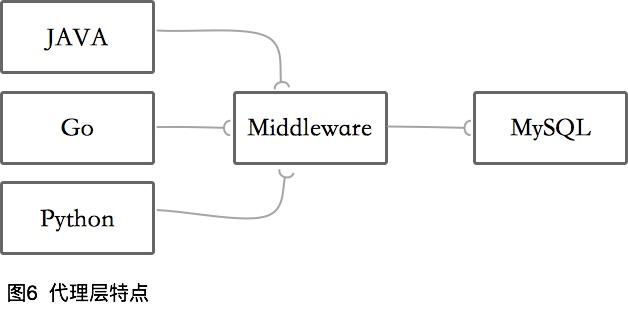
代理层的特点
- 异构支持,DB支持有限
代理层中间件正好相反。仅支持一种后端关系型数据库,但支持多种开发语言。如果你的系统是异构的,并且都有同样的SLA要求,则推荐使用此方案。
- 运维负担大
代理层需要维护数据库连接数量有限(MySQL Router那种粘性连接除外)。但作为一个独立的服务,既要考虑单独部署,又要考虑高可用,会增加很多额外节点,更别提用了影子节点的公司了。
另外,代理层是请求唯一的入口,稳定性要求极高,一旦有高耗内存的聚合查询把节点搞崩溃了,都是灾难性的事故。
综合考虑后,medical-report使用sharding-jdbc做分库分表,将查报告相关的表单独放入一个数据库实例,对yjsj_jianyancgjg和yysy_jianyanbg做分表处理
信息整理
影响业务和项目
yjsj_jianyancgjg的影响:查询检验报告详情,调度Job
yysy_jianyanbg的影响:文字报告、图片报告、健康档案、Job、报告定制
分表字段的选择
现有的查询yjsj_jianyancgjg都是根据机构编号和jianyanid查询,所以可用于分表的字段有jigoubh(机构编号)、jianyanid(医院检验id)。
使用jigoubh分表,是切实可行的,但是数据分布可能不够均匀,比如单单一个金华市中心医院的数据就有1500万
使用jianyanid不一定可行,这个字段存储的是医院的检验id,可能重复,不一定都是数字,可能是字符串。另外用jianyanid分表,对于后面的扩展性不太好。
综合考虑之后,使用customer_id(客户编号)进行分表,由于这两张表都没有customer_id字段,需要用脚本补数据。

sql整理
分表分表前,需要将表结构涉及到的所有sql拉出来,充分评估分表后对原有sql的影响。原有sql很大程度上是需要修改的,比如加上分片字段作为条件。
而在业务中,需要考虑是否能够职称sql改写,会不会缺少参数等。如果缺少,还需要对业务代码进行改造。
历史数据处理

step1: 将现有表结构以及数据迁移到单独的库,对于需要迁移的两张表,先放在临时表中。
step2: 使用脚本分批次查询临时表中数据,插入到分表后的新表
step3: 对于新产生的数据,通过mq的方式,在新系统插入。
step4: 前面三步弄好之后,进行业务迁移,业务迁移完毕之后,关闭DTS数据同步
对数据部分的影响
分库分表的改造,涉及表结构以及数据的变更。需要和大数据部门沟通,让他们配合改造。

